# 什么是有序列特性的数据
- 人类的自然语言,是符合某个逻辑或规则的字词拼凑排列起来的,这就是符合序列特性
- 语音,我们发出的声音,每一帧每一帧的衔接起来,才凑成了我们听到的话,这就是符合序列特性
- 股票,随着时间的推移,会产生具有顺序的一系列数字,这就是符合序列特性
符合时间顺序,逻辑顺序,或者其他顺序就叫序列特性
# RNN
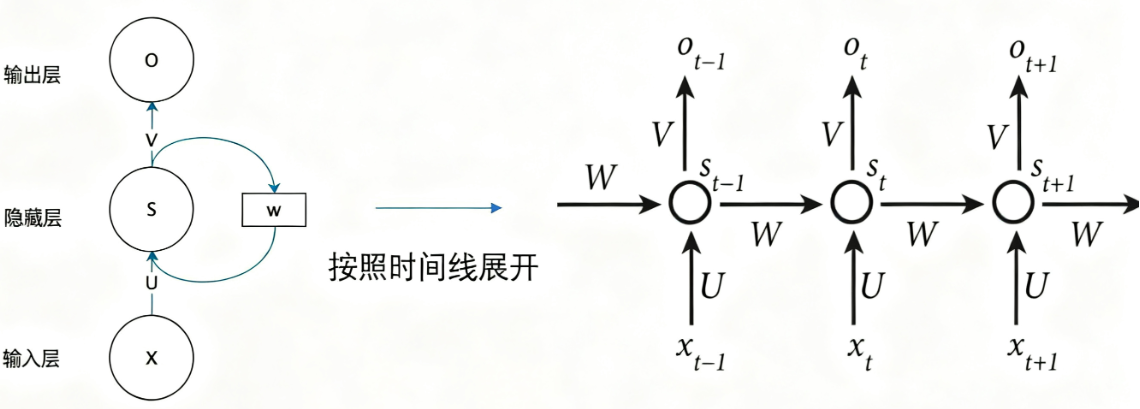
Recurrent Neural Network (RNN) 循环神经网络,是一种用于处理序列数据的神经网络。核心特点是 具有记忆能力,能够在处理当前的输入时,结合之前的输出进行计算
例如,在预测中, 兰欣怡 吃 苹果 和 兰欣怡 是 苹果 的老板 ,如果我们要给 苹果 打上标签,在 全连接神经网络 中,是以正确的概率最大为目标来训练模型,这将导致,语料中,两种苹果谁的数量多,预测的结果就是什么。显然,没有结合上下文的预测是很容易出错的,我们应该结合上下文训练模型,这就是全连接神经网络做不到的事情,因此引入了 循环神经网络
# RNN 数学原理
RNN 的隐藏层不仅接受当前输入,还接受上一时刻的隐藏状态,由此形成” 循环结构 “
ht=f(Wxh⋅xt+Whh⋅ht−1+bh)
- ht:t 时刻的隐藏状态
- xt:当前输入
- Wxh,Whh,bh:可学习的参数(注意,此参数为 共享参数)
![]()
# LSTM
# 为什么要有 LSTM
基础的 RNN,每一时刻的隐藏状态不仅由该时刻的输入决定,还取决于上一时刻的隐藏层的值。如果一个句子很长的话,到句子末尾时,RNN 将记不住句子开头的详细内容。LSTM 利用 门控装置 有效地缓解了这个问题
# LSTM 是什么
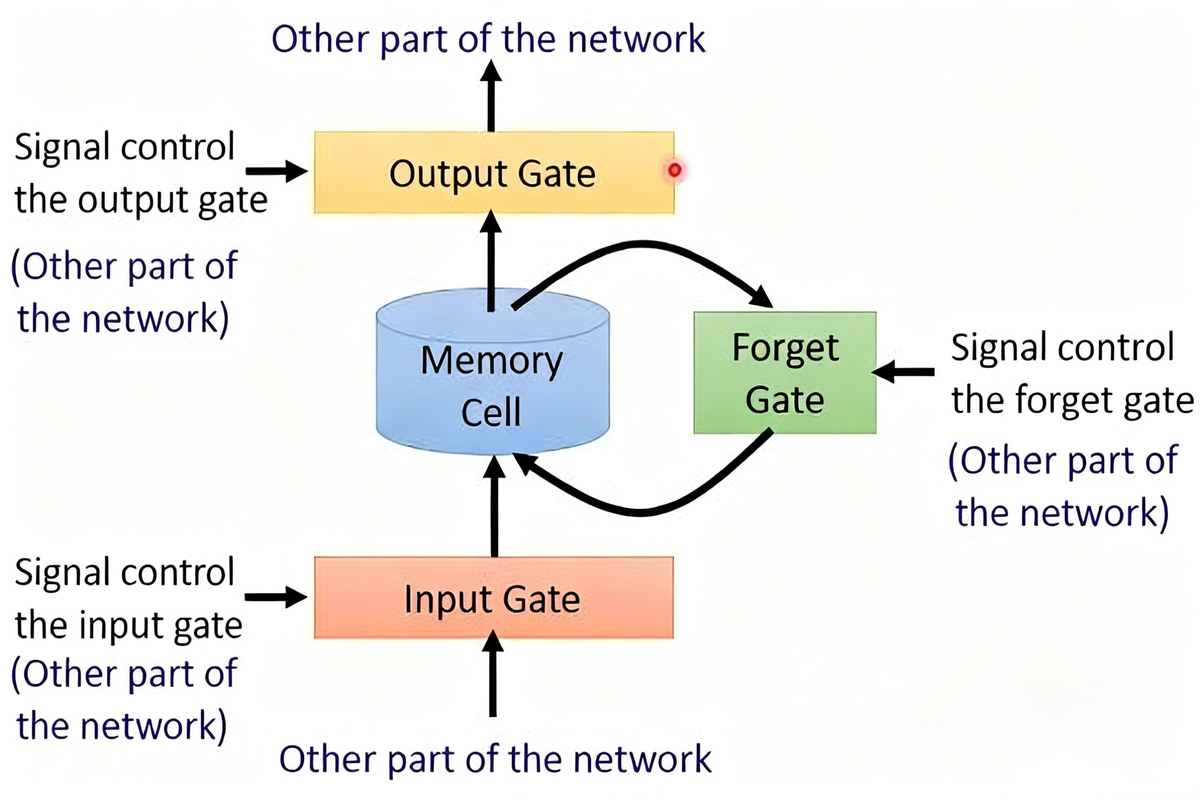
Long Short Term Memory (LSTM),长短期记忆网络相较普通 RNN,多了三个 门
![]()
# LSTM 的数学原理
LSTM 的关键在于引入了 细胞状态 和 门控机制
- 遗忘门:决定哪些历史信息需要 “忘记”
- ft=σ(Wf⋅[ht−1,xt]+bf)
- 输入门:决定哪些新的信息需要存储进细胞状态
- it=σ(Wi⋅[ht−1,xt]+bi)
- C~t=tanh(Wc⋅[ht−1,xT]+bC)
- 输出门:决定当时当刻的输出和隐藏状态
- ot=σ(Wo⋅[ht−1,xt]+bo)
- 状态更新
- 细胞状态更新:Ct=ft⋅Ct−1+it⋅C~t
- 前一状态的 Ct−1 被选择遗忘 ft
- 新候选记忆 C~t 被选择写入 it
- 隐藏状态更新:ht=ot⋅tanh(Ct)
- 输出门 ot 决定当前细胞状态中哪部分流向隐藏层
# GRU
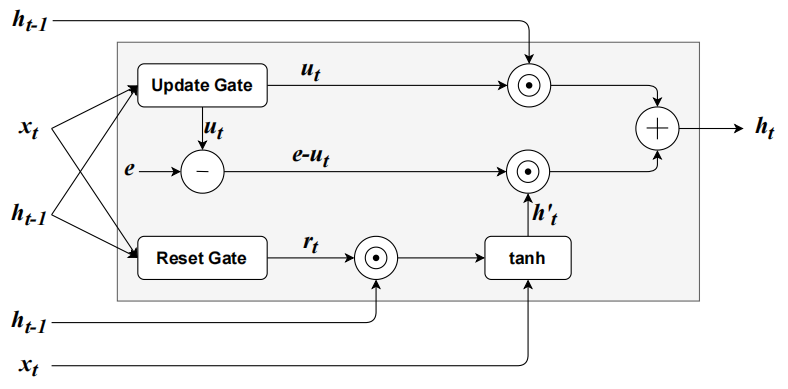
Gate Recurrent Unit (GRU),门控循环单元与普通 RNN 的根本区别在于其支持 更新门、重置门,能很好地捕捉长距离的依赖关系,相比 LSTM 结构更简单,参数更少,可以理解成 LSTM 的简化版
- 没有显式的细胞状态 Ct,而是直接用隐藏状态 ht 传递信息
- 把 LSTM 的遗忘门和输出门合并成更新门
- 另外保留一个重置门,用来决定历史信息在生成候选状态时的影响程度
# GRU 的数学原理
- 更新门:控制新旧信息的平衡
- Zt=σ(Wz⋅[ht−1,xt]+bz)
- 重置门:控制候选状态计算时,对旧信息的依赖程度
- rt=σ(Wr⋅[ht−1,xt]+br)
- 候选隐藏状态:利用重置门决定保留多少过去的信息
- h~t=tanh(Wh⋅xt+Uh⋅(rt⊙ht−1)+bh)
- 隐藏状态更新:利用更新门在旧状态和候选状态之间插值
- ht=(1−zt)⊙ht−1+zt⊙h~t
![]()