# 中文分词 jieba 库
# 分词原理
- 利用中文词库,确定中文字符之间的关联概率
- 中文字符间概率大的组成词组,形成分词结果
- 除了分词,用户还宽裕添加自定义的词组
# 三种模式
- 精确模式:把文本精确切分开,不存在冗余单词
- 全模式:把文本中所有可能的词语都扫描出来,有冗余
- 搜索引擎模式:在精确模式的基础上,对长词再次切分
# 常用函数
# 精确模式
返回一个列表类型的分词结果
精确模式1
2
3
| import jieba as jb
print(jb.lcut('潺潺流水终于穿过了群山一座座'))
|
输出
['潺潺流水', '终于', '穿过', '了', '群山', '一座座']# 全模式
返回一个列表类型的分词结果
全模式1
2
3
| import jieba as jb
print(jb.lcut('潺潺流水终于穿过了群山一座座', cut_all=True))
|
输出
['潺潺', '潺潺流水', '流水', '终于', '穿过', '了', '群山', '一座', '一座座']# 搜索引擎模式
返回一个列表类型的分词结果
搜索引擎模式1
2
3
| import jieba as jb
print(jb.lcut_for_search("潺潺流水终于穿过了群山一座座"))
|
输出
['潺潺', '流水', '潺潺流水', '终于', '穿过', '了', '群山', '一座', '一座座']# 向分词库中新加词
jieba.add_word 是 jieba 分词库中的一个函数,用于向词典中添加新词。通过添加自定义词语,可以提高分词准确性,特别是在处理专业术语、新词或特定领域词汇时
添加词语1
2
3
| import jieba
jieba.add_word("深度学习")
|
# 词云绘制 worldcloud 库
# 用法
以 WordCloud 对象为基础,配置参数、加载文本、输出文件
基础词云1
2
3
4
5
| import wordcloud as wd
c = wd.WordCloud()
c.generate("wordcloud by Python")
c.to_file("pywordcloud.png")
|
# 配置参数
配置参数1
2
3
4
5
6
7
8
9
10
11
12
| import wordcloud as wd
cloud = wd.WordCloud(
width=600, height=400,
min_font_size=10, max_font_size=20,
font_step=2,
max_words=20,
stopwords={"nihao"},
)
|
# 示例
示例1
2
3
4
5
6
7
8
9
| import jieba
import wordcloud
txt = "程序设计语言是计算机能够理解和识别用户\
操作意图的一种交互体系,它按照特定规则组织计算机指令,\
使计算机能够自动进行各种运算处理"
w = wordcloud.WordCloud(width=1000, height=700, font_path="msyh.ttc")
w.generate(" ".join(jieba.lcut(txt)))
w.to_file("pywordcloud4.png")
|
- 为什么一定要
" ".join(jieba.lcut(txt)) ?wordcloud 库的 generate() 方法需要接收一个字符串,这个字符串中的词语需要用空格分隔。库会根据空格将字符串拆分成单独的词语,然后统计词频并生成词云。如果直接使用 "".join(jieba.lcut(txt)) ,所有词语会连在一起, wordcloud 无法正确识别每个词语的边界,导致无法生成正确的词云。
# 复杂网络分析库 networkx
NetWorkX 是一个基于 python 的图论和网络分析库,提供了许多功能
- 灵活的数据结构:NetWorkX 支持多种类型的图,包括无向图、有向图、加权图等,以及节点和边的属性
- 丰富的算法:NetWorkX 提供了大量的图论算法,包括图的遍历、最短路径、社区发现、中心性等,满足各种网络分析需求
- 可视化支持:NetWorkX 提供了简单易用的可视化工具,用于绘制和展示复杂网络结构,帮助用户直观地理解和分析数据
# 创建图
创建图1
2
3
4
5
6
7
8
| import networkx as nx
G = nx.Graph()
G.add_node(1)
G.add_nodes_from([2, 3])
G.add_edge(1, 2)
G.add_edges_from([(1, 3), (2, 3)])
|
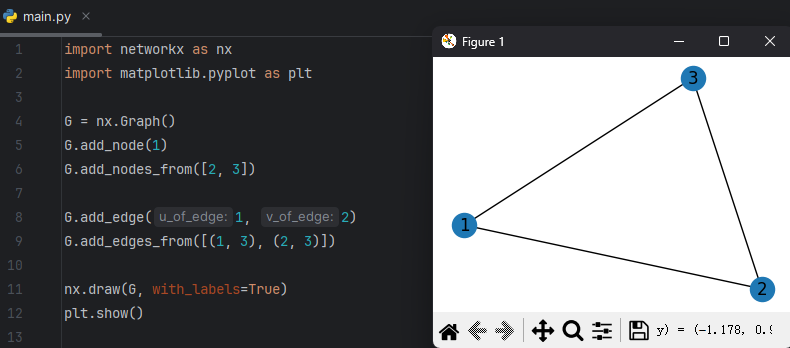
# 绘制图
绘制图1
2
3
4
5
6
7
8
9
10
11
12
| import networkx as nx
import matplotlib.pyplot as plt
G = nx.Graph()
G.add_node(1)
G.add_nodes_from([2, 3])
G.add_edge(1, 2)
G.add_edges_from([(1, 3), (2, 3)])
nx.draw(G, with_labels=True)
plt.show()
|
![]()
# 计算节点度中心性
# 度中心性
度中心性是在网络分析中刻画节点中心性的最直接度量指标。一个节点的节点度越大就意味着这个节点的度中心性越高,该节点在网络中就越重要
# 代码
度中心性1
2
3
4
5
6
7
8
9
10
11
| import networkx as nx
G = nx.Graph()
G.add_node(1)
G.add_nodes_from([2, 3])
G.add_edge(1, 2)
G.add_edges_from([(1, 3), (2, 3)])
degree = nx.degree_centrality(G)
print(degree)
|
上述代码输出
{1: 1.0, 2: 1.0, 3: 1.0}# 查找最短路径
最短路径1
2
3
4
5
6
7
8
9
10
11
| import networkx as nx
G = nx.Graph()
G.add_node(1)
G.add_nodes_from([2, 3])
G.add_edge(1, 2)
G.add_edges_from([(1, 3), (2, 3)])
shortest = nx.shortest_path(G, source=1, target=3)
print(shortest)
|
这个代码查找的是路径,上述代码输出
[1, 3]# 其他功能
包括:
- 社交网络分析
- 生物网络分析
- 交通网络分析
- ...
可以参考传送门