# requests 模块
模拟浏览器发请求
# 使用步骤
- 指定
- 发起请求
- 获取相应数据
- 持续化存储
C++ 1
2
3
4
5
6
7
8
9
10
11
12import requests
url = 'https://www.bilibili.com/'
request = requests.get(url=url)
page_text = request.text
print(page_text)
with open('bilibili.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
# 百度翻译的 "破解"
百度翻译输入单词后,页面做局部刷新( 请求 )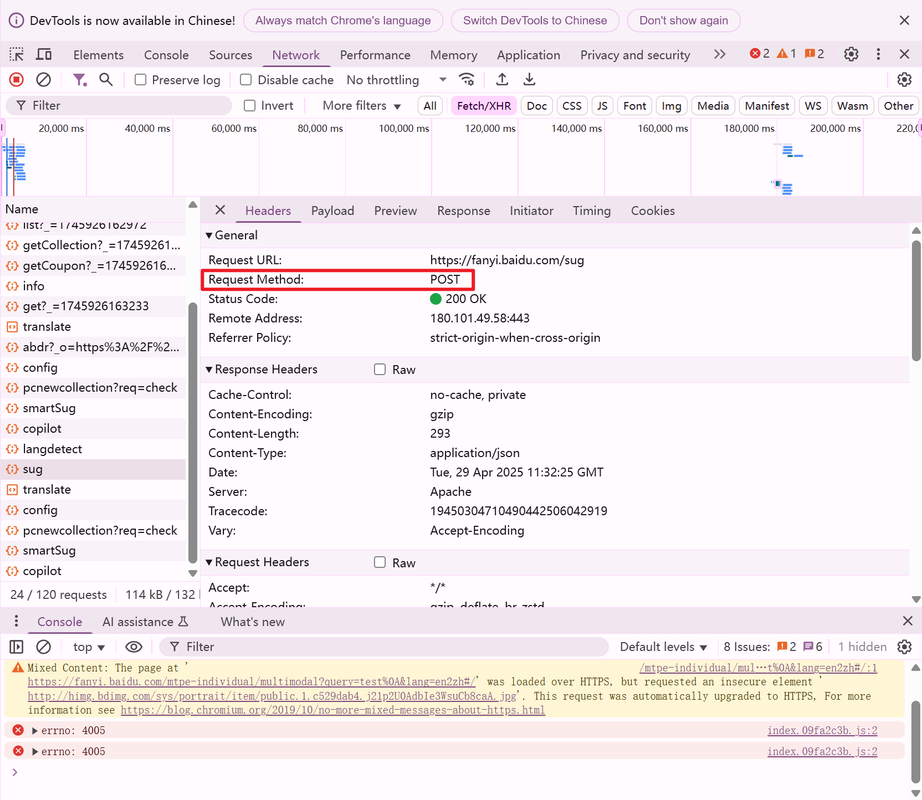
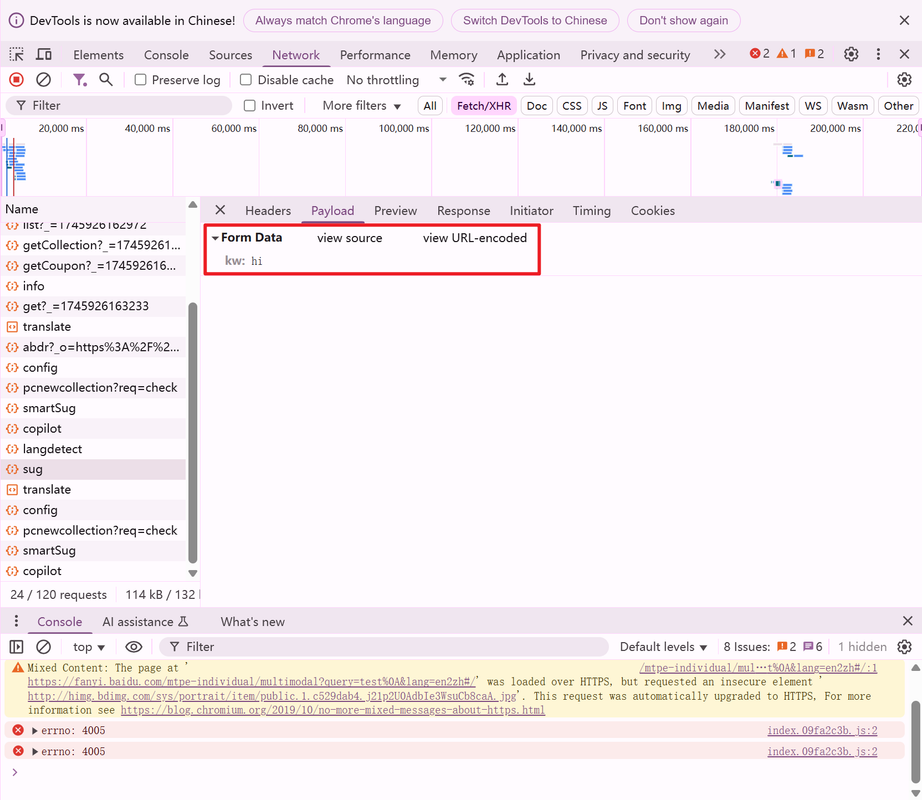
请求,相应数据是一组 数据
- 网站的反爬策略: 检测
- 反反爬策略: 伪装
Python 1
2
3
4
5header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36'
}
request = requests.get(url=url, headers=header)
爬虫代码
1 | import json |
# 豆瓣电影详情数据
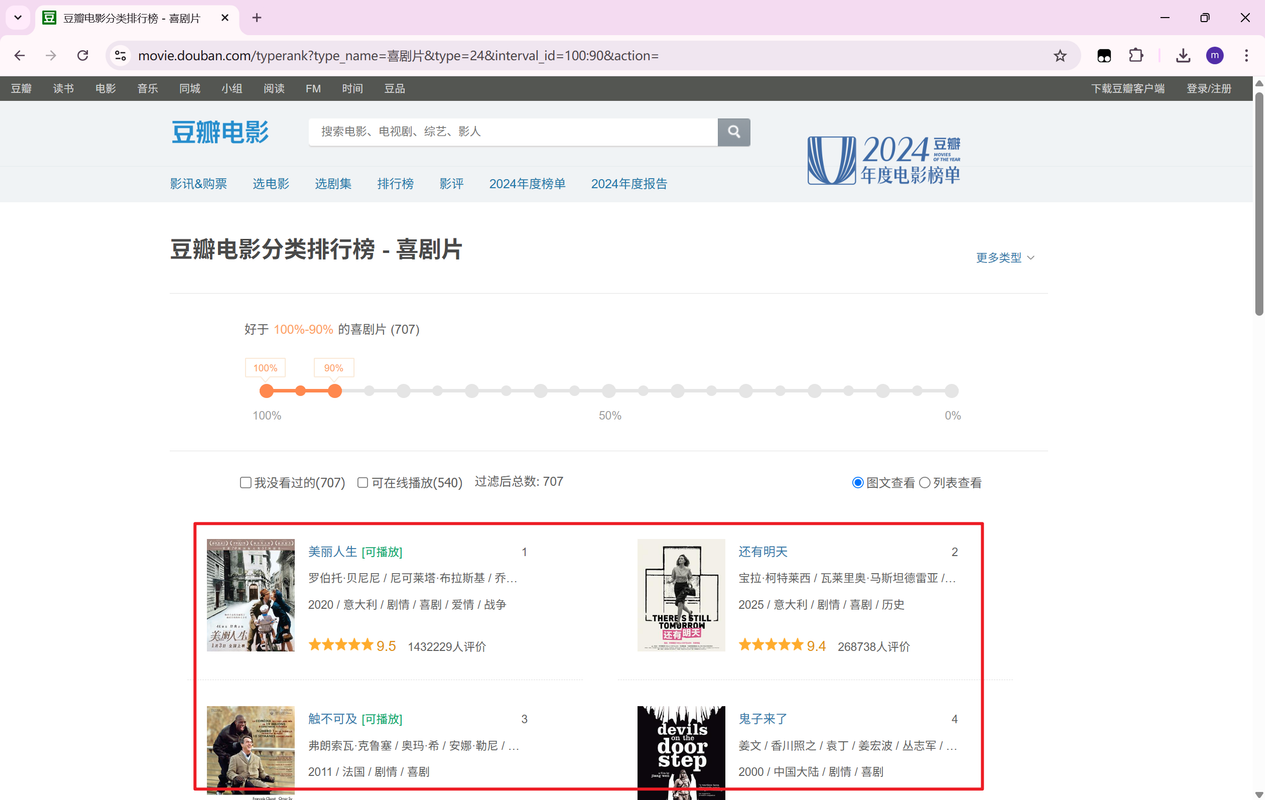
我们需要的是页面的局部信息,目前,暂时不考虑页面的数据解析( 请求)