# 什么是数据库数据库( D a t a b a s e Database D a t a b a s e R D B M S RDBMS R D B M S R e l a t i o n a l D a t a b a s e M a n a g e m e n t S y s t e m Relational~Database~Management~System R e l a t i o n a l D a t a b a s e M a n a g e m e n t S y s t e m
数据以表格的形式出现 每行为各种记录名称 每列为记录名称所对应的数据域 许多的行和列组成一张表单 若干的表单组成 d a t a b a s e database d a t a b a s e # RDBMS 术语数据库: 数据库是一些关联表的集合。数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。列: 一列 (数据元素) 包含了相同类型的数据,例如邮政编码的数据。** 行:** 一行(元组,或记录)是一组相关的数据,例如一条用户订阅的数据。 冗余 :存储两倍数据,冗余降低了性能,但提高了数据的安全性。主键 :主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。** 外键:** 外键用于关联两个表。 复合键 :复合键(组合键)将多个列作为一个索引键,一般用于复合索引。** 索引:** 使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
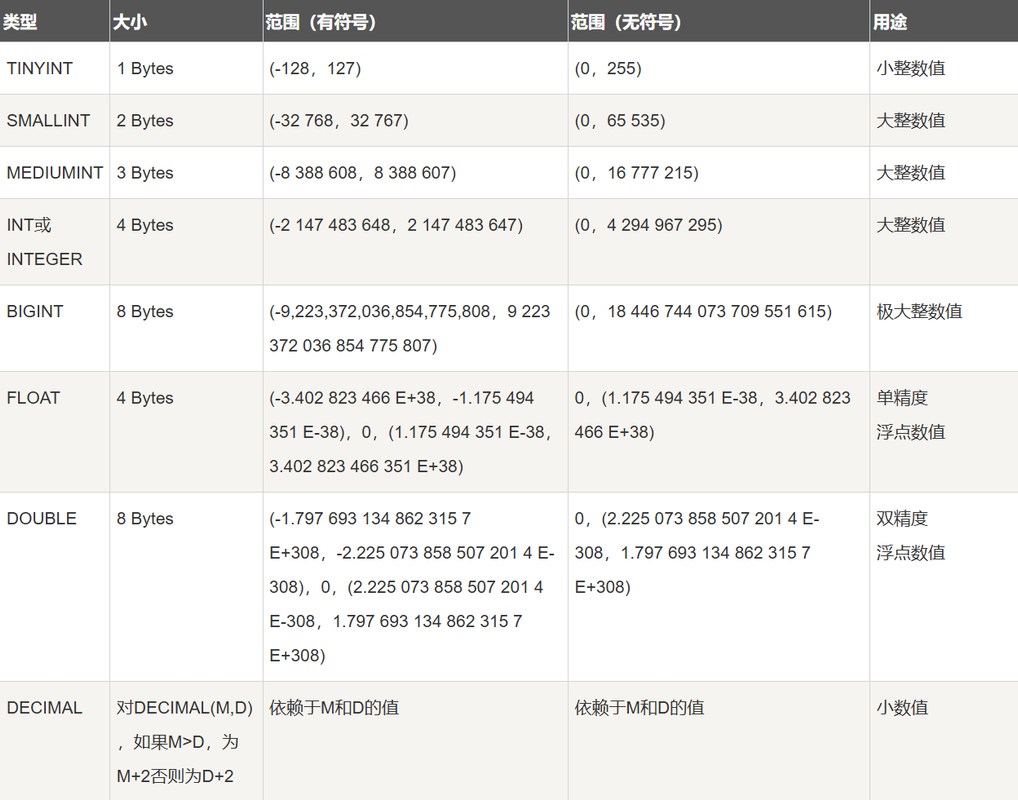
# 数据类型# 数值类型
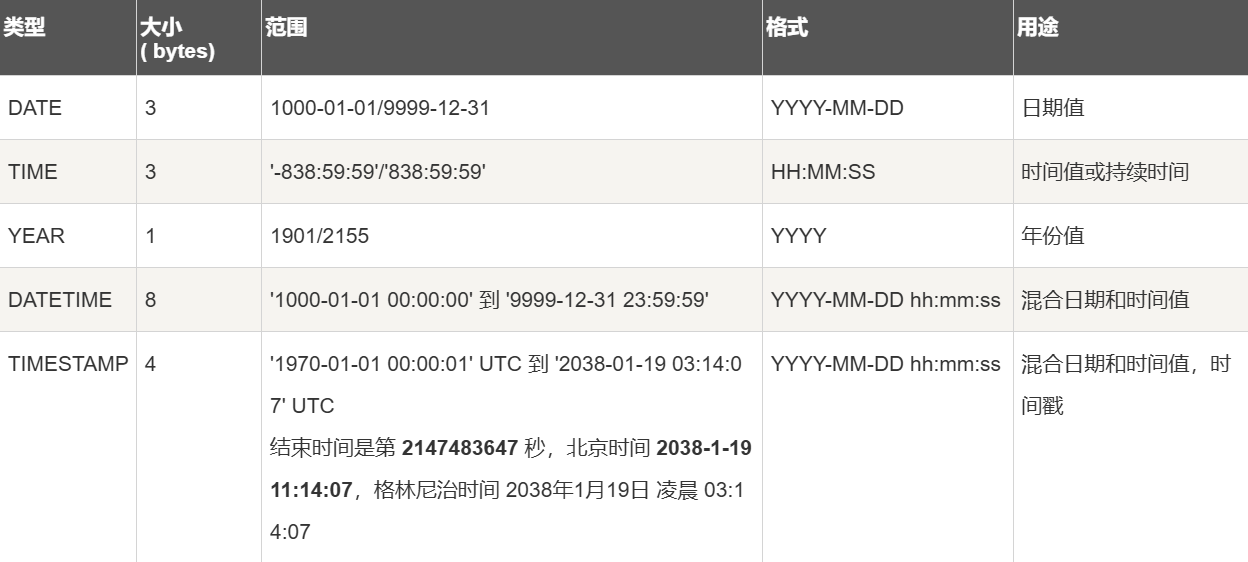
# 日期 / 时间类型每个时间类型有一个有效值范围和一个 "零" 值,当指定不合法的 MySQL 不能表示的值时使用 "零" 值。
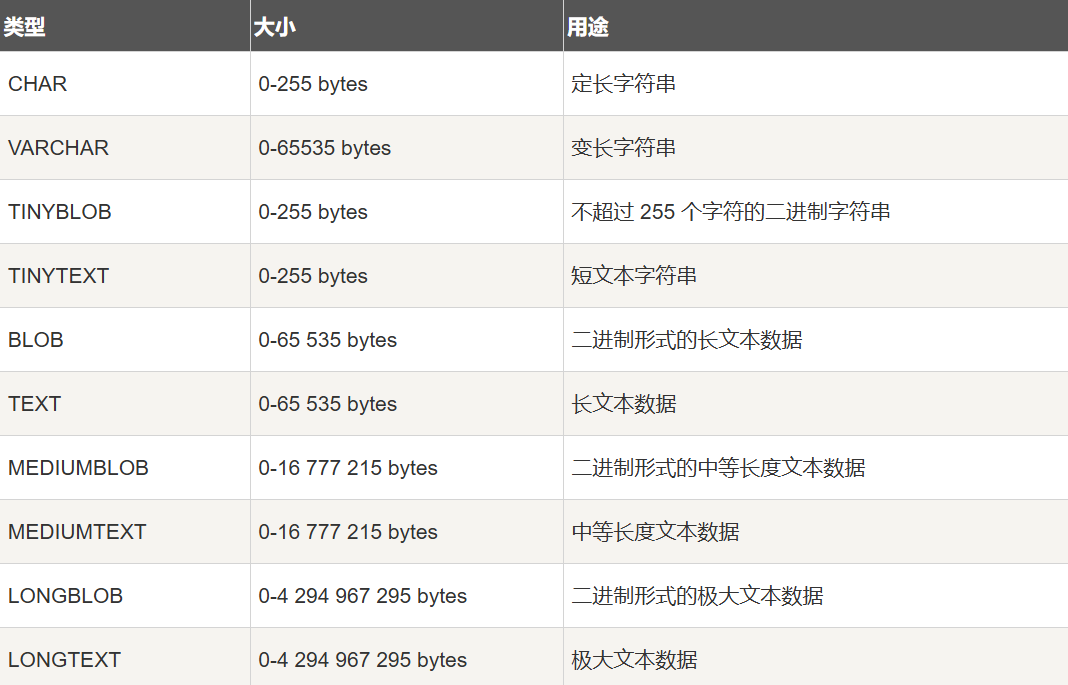
# 字符串类型
# 注意char(n) 和 varchar(n) 的括号的 n n n char 和 varchar 类型类似,但保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。# 枚举和集合类型enum :枚举类型,用于存储单一值,可以选择一个预定义的集合set :集合类型,用于存储多个值,可以选择多个预定义的集合# 空间数据类型GEOMETRY , POINT , LINESTRING , POLYGON , MULTIPOINT , MULTILINESTRING , MULTIPOLYGON , GEOMETRYCOLLECTION : 用于存储空间数据(地理信息、几何图形等)。
# 数据库的命令mysql -u 用户名 -p :连接数据库use 数据库名 :选择要操作的 M y S Q L MySQL M y S Q L show databases; :列出所有数据库show tables; :显示指定数据库的所有表( use 数据库 是这个命令的前置操作)show columns from 数据表 :显示数据表的属性、属性类型、主键信息、是否为 N U L L NULL N U L L show index from 数据表 :显示数据表的详细索引信息,包括主键create database 数据库名; :创建数据库如果存在该名字的数据库,将会报错 可以使用 create database if not exists 数据库名; drop database 数据库名; :删除数据库如果不存在该名字的数据库,将会报错 可以使用 drop database if exists 数据库名; # 创建数据表创建数据库需要以下信息
# 语法
1 2 3 4 5 create table 表名 ( 列名1 数据类型, 列名2 数据类型, ... );
# 实例
1 2 3 4 5 6 7 CREATE TABLE users ( id INT AUTO_INCREMENT PRIMARY KEY , username VARCHAR (50 ) NOT NULL , email VARCHAR (100 ) NOT NULL , birthdate DATE , is_active BOOLEAN DEFAULT TRUE );
id :用户 i d id i d username :用户名,变长字符串,不许为空is_active :用户是否激活,布尔类型,默认为 t r u e true t r u e # 删除数据表drop table 表名; :直接删除表,不检查是否存在drop table if exists 表名; :检查是否存在,如果存在才删除truncate table 表名; :删除表中所有数据,但保留表的结构# 针对表中数据# 插入数据
1 2 3 4 5 6 insert into 表名 (列名1 , 列名2 , ...)value (数值1 , 数值2 , ...);insert into user (name, email, birthDate, isActive)values ('duoxichangan' , '3200513041@qq.com' , '2006-03-20' , true )
如果你要插入所有列的数据,可以省略列名。N U L L NULL N U L L id 列生成一个唯一的值。
# 查询数据
1 2 3 4 5 select 列名1 , 列名2 , ...from 表名[where condition ] [order by 列名 [ASC | DESC ]] [limit number];
[WHERE condition] :可选语句,用于指定过滤条件[ORDER BY 列名 [ASC | DESC]] :可选语句,用于指定结果集的排序顺序,默认升序( A S C ASC A S C LIMIT number :可选语句,限制返回的行数
1 2 3 4 5 6 select * from user where isActive = true order by birthDate DESC limit 10 ;
# 条件语句 WHERE在 w h e r e where w h e r e = , < , > , <= , >= , != ),逻辑运算符(如 AND , OR , NOT ),以及通配符(如 % )等。
1 2 3 4 5 6 7 8 9 10 11 SELECT * FROM users WHERE username LIKE 'j%' AND is_active = TRUE ;SELECT * FROM users WHERE is_active = TRUE OR birthdate < '1990-01-01' ;SELECT * FROM users WHERE birthdate IN ('1990-01-01' , '1992-03-15' , '1993-05-03' );SELECT * FROM orders WHERE order_date BETWEEN '2023-01-01' AND '2023-12-31' ;
# 模糊搜索 LIKE
1 2 SELECT * FROM employees WHERE last_name LIKE 'sm_i%' COLLATE utf8mb4_general_ci;
# 连接操作符 UNIONU N I O N UNION U N I O N S E L E C T SELECT S E L E C T U N I O N UNION U N I O N S E L E C T SELECT S E L E C T S E L E C T SELECT S E L E C T
1 2 3 4 5 6 7 8 SELECT 列名1 , 列名2 , ...FROM 表名1 WHERE condition1UNION SELECT 列名1 , 列名2 , ...FROM 表名22 WHERE condition2[ORDER BY column1, column2, ...];
如果想保留重复行的话,可以把 UNION 换成 UNION ALL
# 排序语句 ORDER BY
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 order by birthDate ASC ;order by birthDate DESC , number ASC ;order by 3 DESC , 1 ASC SELECT productName, price * discountRate AS discountedPriceFROM productsORDER BY discountedPrice DESC ;SELECT product_name, priceFROM productsORDER BY price DESC NULLS LAST ;ORDER BY price DESC NULLS FIRST ;
# 分组语句 GROUP BY
1 2 3 4 SELECT 列名, aggregate_function(column2)FROM table_nameWHERE condition GROUP BY 表名;
aggregate_function(column2) :对分组后的每个组执行的聚合函数。
1 2 3 SELECT customerId, SUM (orderAmount) AS totalAmountFROM ordersGROUP BY customerId;
我们使用
GROUP BY customerId 将结果按
customerId 列分组,然后使用
SUM(orderAmount) 计算每个组中
orderAmount 列的总和。
AS totalAmount 是为了给计算结果取一个别名,使查询结果更易读。
GROUP BY 子句通常与聚合函数一起使用,因为分组后需要对每个组进行聚合操作SELECT 子句中的列通常要么是分组列,要么是聚合函数的参数可以使用多个列进行分组,只需在 GROUP BY 子句中用逗号分隔列名即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 mysql> SELECT * FROM employee_tbl; + | id | name | date | signin | + | 1 | 小明 | 2016 -04 -22 15 :25 :33 | 1 | | 2 | 小王 | 2016 -04 -20 15 :25 :47 | 3 | | 3 | 小丽 | 2016 -04 -19 15 :26 :02 | 2 | | 4 | 小王 | 2016 -04 -07 15 :26 :14 | 4 | | 5 | 小明 | 2016 -04 -11 15 :26 :40 | 4 | | 6 | 小明 | 2016 -04 -04 15 :26 :54 | 2 | + 6 rows in set (0.00 sec)mysql> select name, count (* ) from employeeTbl group by name;+ | name | COUNT (* ) | + | 小丽 | 1 | | 小明 | 3 | | 小王 | 2 | + 3 rows in set (0.01 sec)
# 使用 WITH ROLLUPWITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计 (SUM, AVG, COUNT...) 。如果要将以上的数据表按名字进行分组,再统计每个人登录的次数,则:
1 2 3 4 5 6 7 8 9 10 11 12 mysql> SELECT name, SUM (signin) as signinCount FROM employeeTblGROUP BY name WITH ROLLUP ;+ | name | signin_count | + | 小丽 | 2 | | 小明 | 7 | | 小王 | 7 | | NULL | 16 | + 4 rows in set (0.00 sec)
其中记录
N U L L NULL N U L L 表示所有人的登录次数。
# coalesce 语法:
参数说明:如果
a == null ,则选择
b b b ;如果
b == null , 则选择
c c c ;如果
a != null ,则选择
a a a ;如果
a , b , c a,b,c a , b , c 都为
N U L L NULL N U L L ,则返回为
N U L L NULL N U L L 。
以下实例中如果名字为空我们使用总数代替:
1 2 3 4 5 6 7 8 9 10 11 12 mysql> SELECT coalesce (name, '总数' ), SUM (signin) as signin_count FROM employeeTblGROUP BY name WITH ROLLUP ;+ | coalesce (name, '总数' ) | signin_count | + | 小丽 | 2 | | 小明 | 7 | | 小王 | 7 | | 总数 | 16 | + 4 rows in set (0.01 sec)
# 更新数据
1 2 3 update 表名set 列名 = 值1 , 列2 = 值2 , ...[where condition ];
可以同时更新一个或多个字段 可以在一个单独表中同时更新数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 UPDATE employeesSET salary = 60000 WHERE employee_id = 101 ;UPDATE ordersSET status = 'Shipped' , ship_date = '2023-03-01' WHERE order_id = 1001 ;UPDATE productsSET price = price * 1.1 WHERE category = 'Electronics' ;UPDATE customersSET total_purchases = ( SELECT SUM (amount) FROM orders WHERE orders.customer_id = customers.customer_id ) WHERE customer_type = 'Premium' ;
注意: 在使用 U P D A T E UPDATE U P D A T E W H E R E WHERE W H E R E
# 删除数据
1 2 delete from 表名[where condition ];
如果没有指定 w h e r e where w h e r e 可以在 w h e r e where w h e r e 可以在单个表中一次性删除记录
1 2 3 4 5 delete from customerswhere customerId in ( select customerId from orders where orderDate < '2023-01-01' );